Nuts and Bolts: Reverse Balance Engineering (part 1)
Sergey Anankin, producer
About the subject matter
When developing and launching a game we inevitably draw on expertise and experience of other teams and other projects in every aspect – from designing a gameplay (flappy birds rules!) to choosing a pull strategy (for example, great virality = low Acquisition Cost, Candy Crush forever).
The math model settling the game complexity and controlling business cycles is no exception. When trying to create a perfect balance inside your own game one of the key success factors is an in-depth analysis of other similar successful projects. This analysis helps to understand their mathematical core – a number of laws that rule the game economics and the gameplay. Later on you can use these laws in your own project adjusting them to the features of your own game when necessary. The process of detecting these math laws is what we call reverse engineering (“engineering” – project development, “reverse” – backward).
In this article we’ll try to make out what exactly this reverse engineering is, how this process is organized, what we have to work with in the end and what its fruit are.
As always this article is no guide for action and contains no exact laws, it just reflects our own experience in this matter and our approaches to understanding and implementation of the reverse engineering.
1. About formulae and numbers
Let’s take two variables one of which depends on the other. For instance, E – is the amount of experience required for a player to move up to the next level, and x – the player’s current level. Suppose E depends on x (i.e. being on the first level a player needs to gain 10 experience points to move to the next second level, and being on the fifth level he needs 100 experience points to move to the next sixth level).
The x-dependence of E is usually written like E(x) and it is said E – is a function of x argument (that’s why E is written in a capital letter, and x – in a lower case letter). Such dependence may be represented in these ways:
- Continuous, with the help of an equation (for example, E(x) = x2);
- Discrete, with the help of a table (each x-value has a corresponding E-value).
The main difference between the continuous and discrete dependences is in the following: if the function is defined continuously its value can be obtained with any argument-value (of course, if the function-value can be calculated at all for this argument-value). But what does it all mean?
Having a table function definition you know its value only for the pre-chosen argument values (in our example these are values of x = 1, 2, 3, 4, 5 and so on). If you have an equation you can find the function value not only for x = 1, 2, 3, 4, 5 and so on, but also for any other values – for example, for x = -2 or x = 3.75. In our example with experience and levels values of x = -2 or x = 3.75 have no sense (experience – is a positive integer!), but just fancy for a second what if your table finishes with the value of x = 100 and you need to know how much experience a player must have for moving from the 101st to the 102nd level? To answer this question you’ll need an equation.
From the beginning when analyzing some other (someone else’s) project you get only a discrete formula for each function of the game. Imagine that you want to create a farm and you take the balance of some popular game of the same genre as a guide. You move from one level to another and put down how much experience you need to get to the next level. Having completed 100 levels you get a discrete formula of E(x) function – a table with 100 lines, one for each integer of x starting from 1.
Lots of questions might arise to this table. For instance: what is E value for x = 150? How are these figures chosen? How quickly will they increase with increase of x? Does the speed of these figures increase go up or down?
Thus we’ve come close to the main tasks of the reverse engineering. The reverse engineering of the project mathematics in the first place serves to detect dependences in a game and in the second to get a continuous notation of these dependences. The first thing will help us to understand which of the game variables are interrelated. The second thing (i.e. an equation) gives us an opportunity to use these dependences as we think fit and to modify them according to our own needs.
2. Discretization, approximation and other stuff
You should know it’s rather easy to move from a continuous formula to a discrete one. Having an equation you can gradually substitute in it different argument values and get corresponding function values. In our example if we substitute x = 1, 2, 3, 4, 5 and so on to the equation E(x) = x2, we’ll get the following values E = 1, 4, 9, 16, 25 and so on. This process is called function discretization.
The reverse process (getting an equation from the table of values), which is called approximation, is much more difficult as a rule. This process is of special interest to us. Before talking about how we are going to approximate let’s get a clear picture of why we need it at all.
Using correct terminology we can outline the following tasks which can be accomplished with the help of approximation:
- Interpolation, i.e. getting intermediate values of the function (remember the example with finding E for x = 2.5, which doesn’t have much sense in case with levels, but in other cases it may give you some pain in the neck if you have only a table notation of the function);
- Extrapolation, i.e. getting values beyond the limits of the pre-defined area (this task has to be accomplished in case the table finishes with x = 100 and you need to find E for x = 150);
- Analysis, i.e. getting information about the function behaviour (in other words, getting a picture of the current situation). For instance, what can one say about “the next level” experience increase having the formula E(x) = x2? The apparent conclusion is: E increases with the increase of x, i.e. the higher the level is, the more experience a player needs to move up. The less apparent conclusion is: speed of E increase is not only positive, but it rises too. That means the further a player has moved, the bigger per cent the required experience for the next level increases by. After finding the function it is possible within the framework of its analysis to compare it with other functions in order to understand which of them increase faster and which more slowly and thus to see how the game balance changes over time for the player.
3. Detection of dependences
Our first task (before the approximation has any sense) is to detect those dependences the continuous notation of which we’d like to get. As a rule, game cycles are based on a huge variety of different dependences, both simple and complex.
In our example x-dependence of E is detected approximately. In a game of “farm” type the amount of experience required for moving up to the next level can hardly depend on the character’s current equipment or the character’s quantity of friends.
As a matter of fact when analyzing a project you may find much more complex dependences. The following steps can be distinguished to detect them:
- To form a primary list of game variables that can depend on some others (in our case the price of some item in the shop, for instance, most probably depends on the level or its characteristics and the characteristics in their turn may depend on the level or vice versa);
- To form a primary list of variables that either are most likely independent or the law of their formation is absolutely clear (for instance, the number of the next level is always – the previous +1, and the new level reward is always +1 coin);
- To make a list of all the dependences that are potentially possible (for instance, the item price depends on its level, the item price on its properties, its level on its properties and so on);
- To study these potential dependences in order to find out whether they are real dependences or they are just random numbers.
When making a list of potential dependences for the analysis it is very important not be afraid to start actually. The secret is rather simple: you’ve got to remember if a chosen dependence turns out to be no dependence at all, you’ll understand it through its analysis and after that you can safely cross it out from your list.
Let’s dwell on the point “primary analysis” which in theory should arouse great concern. Let’s study the following example: suppose in a game we’re going to analyze a player is to grow plants and sell them in his shop. The plants become available for growing on different levels, have different time of ripening and are sold for different amount of coins by the player. One can find various possible dependences here: selling price and time of ripening may depend on the level these plants become available on or they may depend on each other.
In the case mentioned above personally I would start with the parallel analysis of both variants. Suppose there are only 10 plants in the game. Data on each of them is shown below in the table.
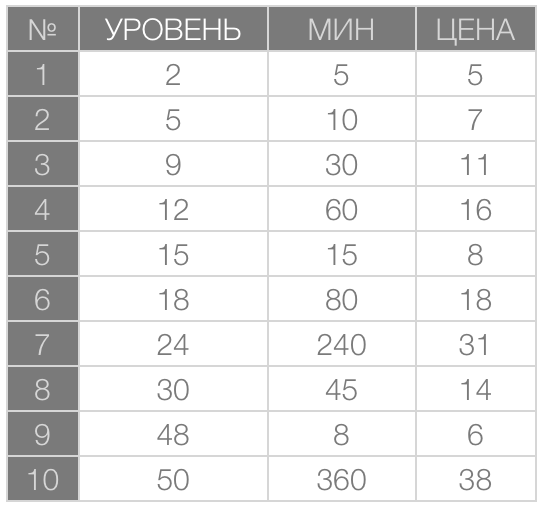
In the left column there’re sequence numbers for each plant (instead of names). In the following columns for each plant there’re an availability level, time of ripening in minutes and a selling price for the shop.
Let’s try to analyze the following dependences:
- Time on level;
- Price on time;
You might find it funny, but I consider plotting a graph of the assumed function according to its table notation to be the most practical way to detect this dependence. It’s easy. We choose two table columns, sort them by the value increasing in the argument column, then we mark on the x-axis values from the argument column and we mark values from the function column on the y-axis.
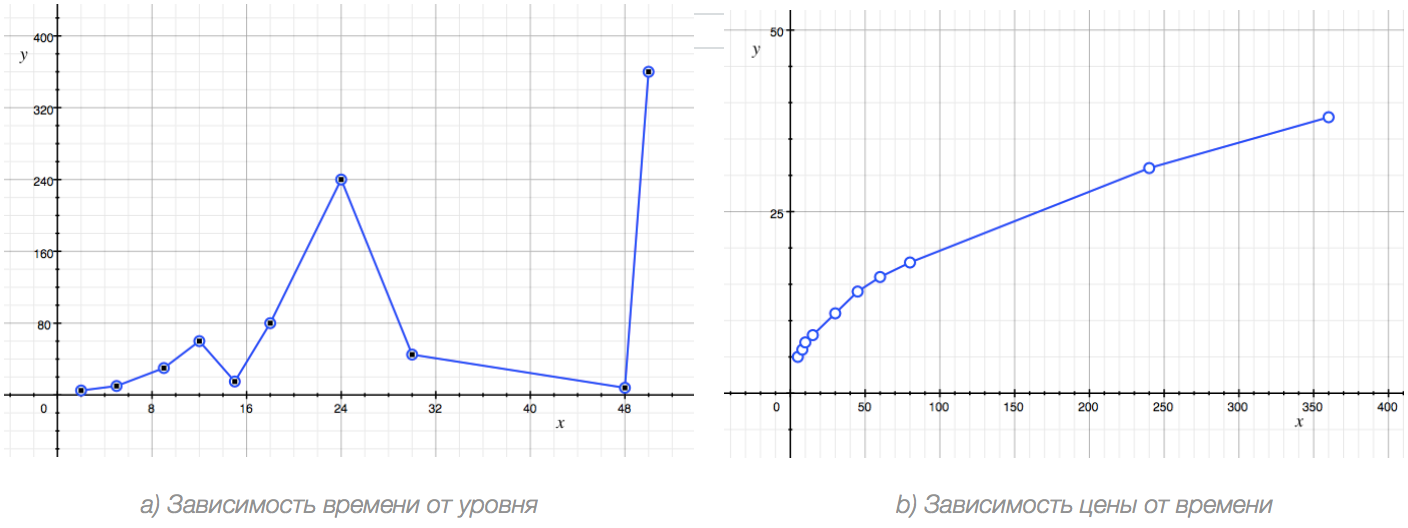
This is what we’ve got. In the left variant values from the MIN column serve as a function and values from the LEVEL column serve as an argument. In the right variant PRICE values serve as a function and MIN values serve as an argument.
There are many ways of approximation of an equation table notation, but as I have already mentioned in reality the most convenient way is to watch a plotted graph. In order to understand if the graph represents a function or a random pattern of points just look at it and ask yourself one simple question: in my thought can I (at least conceptually) continue this graph? We see that in a) case it is hardly possible (we have a zigzag line here which goes up and down and is rather unpredictable). But in b) case it is evident that the graph will be going up and its growth speed will be slowing down. That means that in a) case we have to do with the absence of a function while in b) case we have to do with its presence.
Before you rush to approximate functions and use graphs there’s something else that should be mentioned. Let me make a prediction: even if you approximate the values like an expert the found function will never reflect the table data 100% accurately. There’re two reasons for that:
- Round-off. The formula a balance developer uses doesn’t care how beautiful its figures are. Thus, the square root of two – is a number with an infinite amount of decimal places. It is impossible to put such a figure into the game, so one has to round it off. Note that the round off of small figures makes the data especially inaccurate. For instance, I can round up the square root of two, which is equal to 1.4142135… , to 1.5, and if there must be only whole numbers I can round up to 2 or down to 1, as you understand the difference between them is rather significant. For example, the difference between 100 and 101 is only 1%, while the difference between 1 and 2 is 100%!
- Manual tuning — is a special kind of pain in your neck. Quite often (which is right actually) a developer uses some formula only as a point of departure, i.e. with its help he creates a basic balance version which he tunes manually afterwards taking into consideration such criteria as his own intuition, the game statistics, players’ wishes and so on. Being tuned manually such figures might slightly deviate from the original formula, but at the same time considerably confuse the one who is trying to detect the original law. To get it right let’s study the following example.
Suppose we know that by the 18th level a player starts having some substantial troubles with the game (for instance, he earns too little game money), because of that he gets tired of the game and leaves it forever. We’ve found a very simple solution – we drive the selling price for the plant which a player can get on the 18th level (sequence number 6 in our table) up to 50 so that the player could get a powerful source of income and could get his second wind (such example is a little bit exaggerated, but rather illustrative).
Below here are two graphs – the original one and the one we’ll get after some manual tuning.
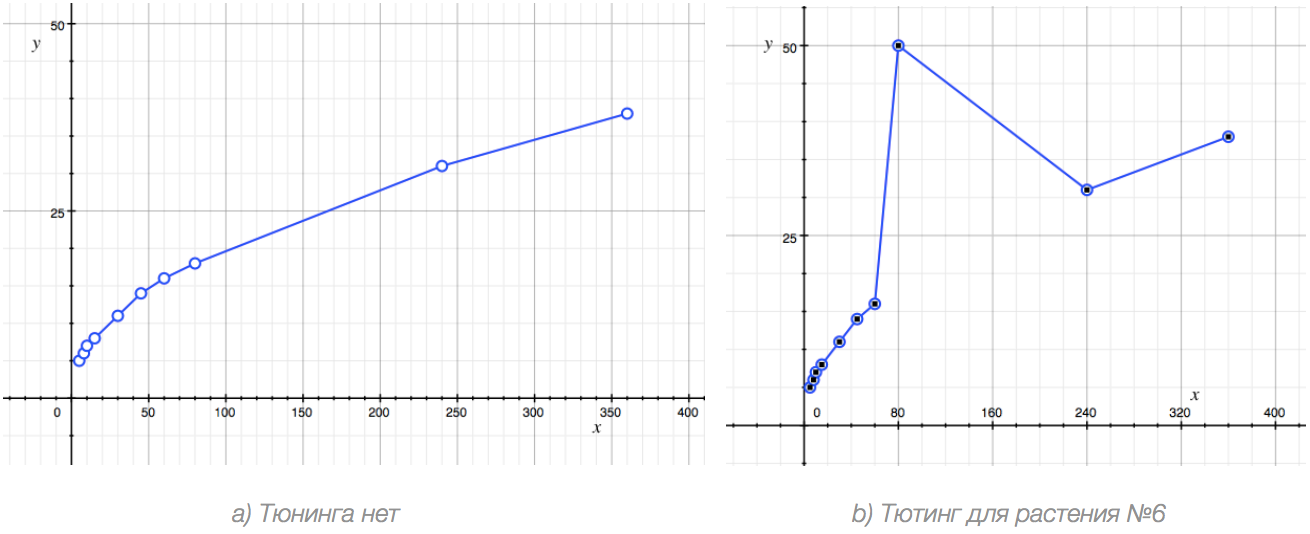
At the right graph you can see a point deviating from the general law. In this case (and in all others in fact) in order not to lose the whole picture the right thing to do is to exclude such points from consideration. If we take away the point (18, 50) and connect the neighbouring points with a straight line we will clearly see a function graph just like on the left.
Our general advice is: don’t let some select figures fool you and don’t be afraid of spikes deviating from the general law. If possible exclude them from consideration for now and try to explain them later.
4. Various types of functions
Well, we have a table according to which we have plotted a graph. We can continue this graph in thought and that means we are facing a function. As I have already mentioned there’re many mathematical ways of approximation but as practice shows we need some natural algorithm which will help us keep in mind the idea of what we are doing.
The first step in such an algorithm is to understand what type of function is represented on the graph we see. Each function type has its own basic run which we can modify later on (shift, squeeze, stretch) by means of scaling factors (i.e. different numerical summands and multipliers we add to the equation).
There’s a great variety of different functions types. Some of them are so complex that it is impossible to understand from their graphs that this is an equation, not a random bunch of points. Fortunately we don’t have to do with them in 99% of cases. Hereafter I will try to list the most useful function types and show you what their graphs look like, so that after you’ve studied this paragraph you could identify the function type through the shape of its graph.
Hereinafter for the sake of simplicity we’ll use the following notation:
- The function argument will be denoted by letter x;
- The function value will be denoted by letter y;
- Notation y = f(x) will mean that variable y is represented by an equation in which x serves as an argument;
- Letters a, b, c and etc. will denote constants, i.e. some figures that appear in the equation f(x) and don’t depend on x.
4.1. Constant function
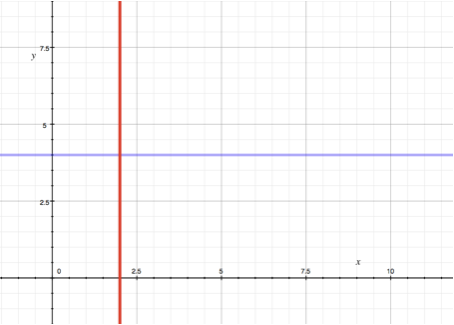
This is the simplest example. In this function equation x and у don’t depend on each other at all!
Examples: y = 4, x = 2.
There’re two functions represented on the left graph. The blue one is described by equation y = a (here function y takes on a value of a with any value of x), and the red one is described by equation x = b (here the argument has a fixed b-value, and y takes on any value).
In fact when y = a, y doesn’t alter no matter what value argument x has. For instance, the amount of a player’s refilled energy a minute is equal to 1 and the level of this player doesn’t matter – this is an example of such function.
4.2. Linear function
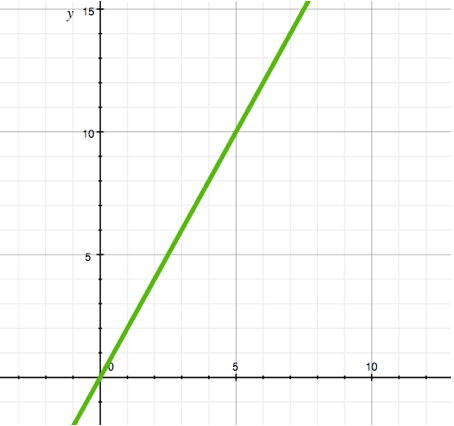
In general this function is described by equation y = a*x + b.
Examples: y = x, y = 2*x + 3, y = 5-x.
Such function graph — is a straight line tilted at any angle to the axes. The left picture represents function y = 2*x, its graph passes through the origin (because with x = 0 the function value is also 0). In a general case this straight line doesn’t have to pass through the origin.
The main feature of a linear function — is constant rate of growth (or rate of decay in case a < 0). Suppose the selling price of a plant linearly depends on the time of its ripening. In this case if plant А ripens two times longer that plant B, its price will be two times bigger as well. It is convenient to define simple laws by a linear function due to its simplicity. For instance, supposing the player’s maximum energy is equal to his level multiplied by one third and rounding it down to a whole number each time we’ll get a simple law: every three levels the maximum energy is one up.
4.3. Power function
This function type has several subtypes which are better to be studied separately. Each of these types is represented by the same formula: y = k*xa + b, but the difference lies in the interval within the bounds of which number a is.
a = 1, a = 0
As you could guess a linear and a constant functions are special cases of a power function. In case a = 1 we have to do with a linear function (y = k*x + b), and in case a = 0 — with a constant one (y = k + b).
a > 1
In this case the function graph is a curve called parabola.
Examples: y = x2, y = 4*x3+3.
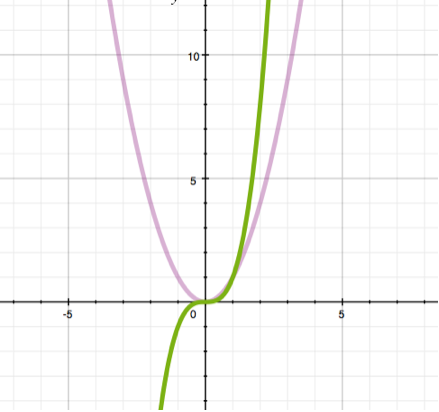
On the left graph you can see functions y = x2 (purple curve) and y = x3 (green curve) represented. As a rule the right upper quarter of the coordinate space is of our main interest (where x and y are positive), but it is also important to understand difference in this function behaviour in other quarters too. Note that the cubic parabola (green) goes down when x becomes less than 0 and continues decreasing, while the square parabola (purple) goes up in the same intercept. In fact any parabola with even-numbered a will never get negative (because negative x when raised to an even power will always be positive) while parabolas with uneven powers can become negative (for instance, -3 raised to the third power evaluates -9).
The main feature of this function is – it allows to arrange growth with increasing speed. As a rule, such functions are used when dealing with game complexity growth, increasing requirements for the players or rise in the deficit. The obvious example we’ve already studied earlier – is growth of experience for a player to move up to the next level. Very often developers use powers 2 or 3 to define this growth. Another example – is time increase of growing plants depending on the level. If the level required to unlock plant A is two times higher than for plant B the time of its ripening will be more than two times longer than the time for plant B.
0 < a < 1
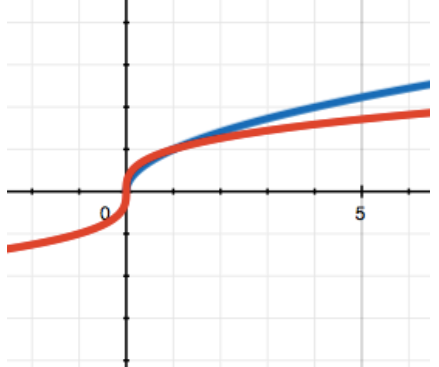
Such function graph looks like a parabola turned through 900.
Examples: y = √x, y = 2* x1/3.
On the graph you can see a square (blue) and cube (red) roots of x. Note again that with x < 0 functions behave differently. The square root of a negative number is not defined at all, while the cube one is.
It’s important to understand that a root of x is still a power function. This is readily illustrated by an example with the second power and a square root. Thus, “x-square” – is x raised to the second power and “square root of x” — is x raised to the 1/2nd power. The power of x can be always represented by fractions where a numerator is the power of x and a denominator is the power of root of x. Thus x raised to the 2/3rd power is a cube root of x raised to the third power.
It should be noted that the power value defines the speed of the function growth by itself. In case a > 1 the bigger a value is, the faster the function grows (see the corresponding graph with cube growing faster than square). Here it’s just the same: 1/2 is bigger than 1/3, so the square root of x will grow faster than the cube one.
We need such functions when we want to slow down the game process. Have a look at our example with the table of plants selling prices depending of the time of plants ripening. The selling price goes up together with the time but this growth slows down. The graph plotted from the table looks very much like a root, doesn’t it?
a < 0
It’s quite easy to make sense of a negative power – it shows that the argument is in the denominator. For example, notation y = x-3 means exactly the same as notation y = 1/x3.
Such function graph is called hyperbola.
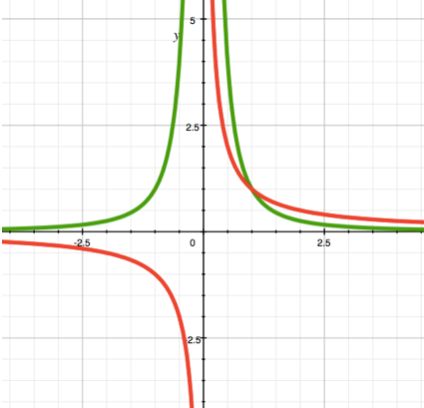
On the left graph you can see functions for a = -1 (red) and a = -2 (green). Note again the difference in the functions behaviour in different parts of the coordinate space. Function a = -1 exists in two opposite quarters (i.e. y will either always have the same sign as x, or it will always have the opposite sign, depending on the constants in the formula), but in case a = -2 the function exists in one half (the sign of y will either always be positive or always be negative depending on the constants in the formula).
We can use this function when we need to arrange some value decrease in the game. Moreover, if a is more than 1 the speed of this decrease will go up (just like with increase in case a > 1), and if a is less than 1 – the speed of decrease will go down (like in case 0 < a < 1).
Generalization
Power functions are the most frequently used in the game designing. They are easy to study, they allow to arrange increase or decrease of any value in the game at a fixed speed which is also very easy to control. All the subtypes of power functions are closely related. Thus, for example, if you find out that y is equal to x raised to the second power you will know for sure that x is equal to the square root of y (at least in the positive part of the space).
There’s a more general form for a power function – the so-called polynomial of degree n. It can be written as the following: y = kn * xn + kn-1 * xn-1 + kn-2 * xn-2 + … + k0 * x0. For instance, the polynomial of the 4th power is y = 2*x4+ 1*x3 + x1 + 3. Here k2 = 0, that’s why we don’t see x2
In practice this function is also often used as it allows to tune the balance more accurately and more finely (in fact, there’re much more “instruments” to adjust your balance this or that way), but this function is more complicated for study and it demands a more substantial mathematical apparatus for the tuning.
4.4. Exponential function
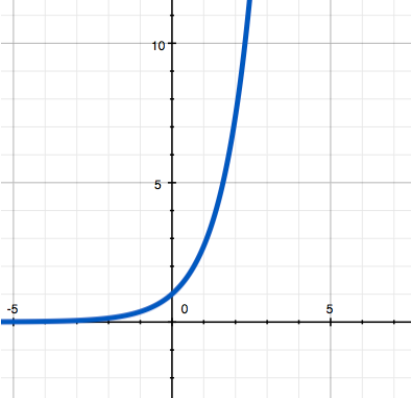
This function can be written as y = k * ax. The argument here doesn’t serve as the base of the power (i.e. what is raised to the power), but as its exponent (i.e. a number showing the power). A constant serves as a base.
A demonstrative example, shown on the left graph, is the popular function “exponential” which we consider to be the carte-de-visite of Asian MMORPG balance. Exponential is represented y = ex, where e — is a famous special number possessing a wide range of remarkable mathematical properties. Approximately it is equal to 2.718281828 (it’s easy to remember – numbers 2 and 7 are twice followed by Leo Tolstoy’s year of birth =).
Such function graph looks like a parabola, but it goes up (or down if a is less than 1) much faster. With small values of a (for instance, 1.000000001) an exponential function will grow more slowly but still sooner or later it will outrun any power function.
An exponential function is used when one needs to arrange a very rapid growth of some value in the game (in Asian MMORPG this function is used to increase amount of experience required for a player to move up to the next level in order to arrange a fast slowdown of the player’s progress through levels).
4.5. Logarithmic function
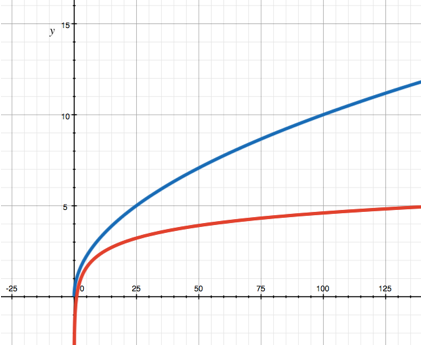
In my calculations I seldom use logarithmic function but I’m bound to mention it in this article. If happens we come across one when analyzing some game balance we should be ready to recognize this function.
Logarithm of x to the base a – is a power to which a should be raised in order to find x. Thus, notation y = logax — is the same as ay = x.
It follows from this definition that logarithmic function is inverse to exponential function, i.e. if we know that y – is a logarithm of x to the base a, we can get an inverse law: x – is a raised to the power y.
On the graph above the logarithm to the base e (red) is shown in comparison with a square root (blue). The most frequently used logarithms are to the base 2 (binary), e (linear) and 10 (common), and the bigger the base is, the higher the graph is. Also note that if the base a < 1, the logarithmic function is decreasing.
As it appears from the said above logarithmic function is useful in case two variables are bound by an exponential rule. This rule is too sharp and in the majority of cases can hardly be a good base for a game balance engineering. However it does have sense in case you want “to draw up the nuts” at the later stages of the game, for instance in order to stretch the time within which a player would drain the rest of the contents and leave until the next game update. As far as I remember Blizzard quite often did so with its World of Warcraft at the dawn of its existence.
4.6. Trigonometrical functions sin and cos
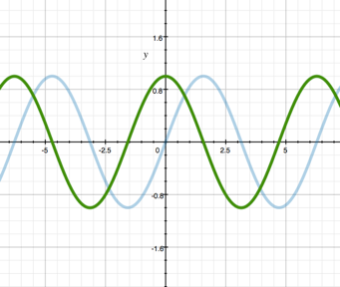
These are also very seldom used when engineering a game balance, but I think it necessary to mention them here.
You can see graphs y = sin(x) (blue) and y = cos(x) (green). Their special feature is periodicity. You can use them in case you want to arrange periodicity and repetitiveness in the game. For instance, if there’re different seasons in your game then harvesting capacity (or the nation’s happiness) can change under the similar law (grows in summer and falls in winter).